Have you ever wondered how to convert a Java character to lowercase efficiently? As programmers, we often encounter scenarios where text manipulation is crucial, especially when it involves changing the case of characters in Java. Whether it's for standardizing user input, handling case-insensitive comparisons, or preparing strings for display, the ability to convert characters from uppercase to lowercase is a fundamental skill in Java programming. This guide will walk you through everything you need to know about converting Java characters to lowercase, ensuring you can handle such tasks with ease and confidence.
Java, as a versatile programming language, offers multiple ways to manipulate character cases, making it both powerful and flexible for developers. For those new to Java or even experienced developers looking to refresh their skills, understanding the nuances of character conversion can significantly enhance your coding prowess. This article aims to provide an in-depth exploration of the methods and best practices for transforming Java characters to lowercase, along with real-world examples to solidify your understanding.
Converting characters to lowercase is not merely a trivial task. It involves understanding Java's character handling capabilities and leveraging them to achieve efficient, accurate results. By delving into this guide, you'll gain valuable insights into the inner workings of Java's character processing, allowing you to write more robust and error-free code. Let's embark on this journey to master the art of converting Java characters to lowercase, ensuring you have the expertise and authority to tackle any case conversion challenge that comes your way.
Table of Contents
- Understanding Java Characters
- Importance of Case Conversion
- Basic Methods for Case Conversion
- Using the toLowerCase() Method
- Handling Non-English Characters
- Performance Considerations
- Real-World Applications
- Common Pitfalls and How to Avoid Them
- Advanced Techniques for Lowercase Conversion
- Best Practices for Character Handling in Java
- Troubleshooting Case Conversion Issues
- Future Trends in Java Character Processing
- FAQs
- Conclusion
Understanding Java Characters
Java characters are an integral part of the Java programming language, representing the building blocks for strings and text manipulation. In Java, the char data type is used to store single 16-bit Unicode character, which allows for a wide range of characters beyond the standard ASCII set. This makes Java well-suited for handling international text and symbols.
Each char in Java is essentially a numeric representation of a character, which can be used for a variety of operations, including arithmetic and logical comparisons. Understanding the nature and behavior of Java characters is essential for effective text manipulation, as it sets the foundation for various string operations, including conversion between uppercase and lowercase.
In Java, characters are indexed using the Unicode standard, which assigns a unique number to every character, regardless of platform, program, or language. This universal standard ensures that Java can handle a vast array of characters, including those from non-English languages, special symbols, and even emojis. As such, mastering Java characters is crucial for building robust, internationalized applications.
Importance of Case Conversion
Case conversion is a fundamental aspect of text processing and manipulation in Java. It involves changing the case of characters from uppercase to lowercase, or vice versa, to meet specific application requirements. The importance of case conversion cannot be overstated, as it plays a vital role in ensuring data consistency, facilitating case-insensitive comparisons, and preparing strings for display or storage.
In many applications, text data may be entered by users in varying cases, which can lead to inconsistencies in data processing and storage. By converting characters to a uniform case, developers can standardize data input, making it easier to compare, search, and manipulate. This is particularly important in scenarios where case-sensitivity could lead to errors or unexpected behavior, such as searching for usernames or email addresses.
Moreover, case conversion is essential for tasks such as formatting text for display, ensuring that output is consistent and visually appealing. For example, converting all text to lowercase can create a uniform look for certain user interfaces or reports. Overall, understanding and implementing case conversion techniques is crucial for developing efficient, reliable Java applications.
Basic Methods for Case Conversion
Java provides several basic methods for converting characters between uppercase and lowercase. These methods are part of the Character class, which offers a range of utilities for character manipulation. Understanding these basic methods is the first step in mastering case conversion in Java.
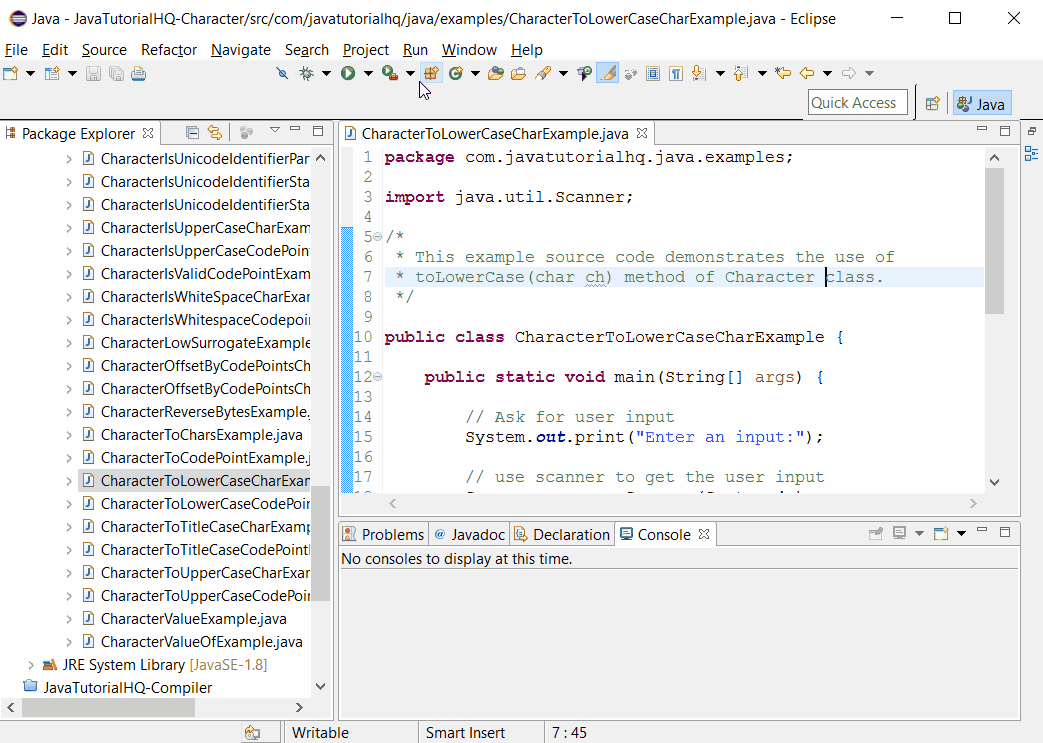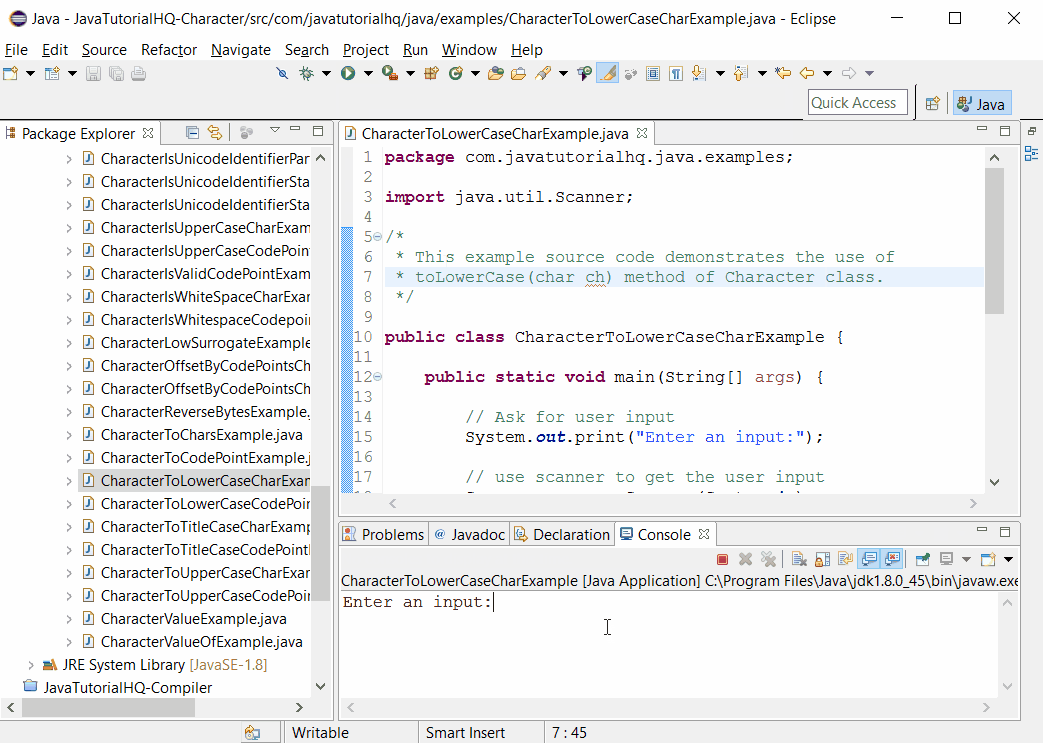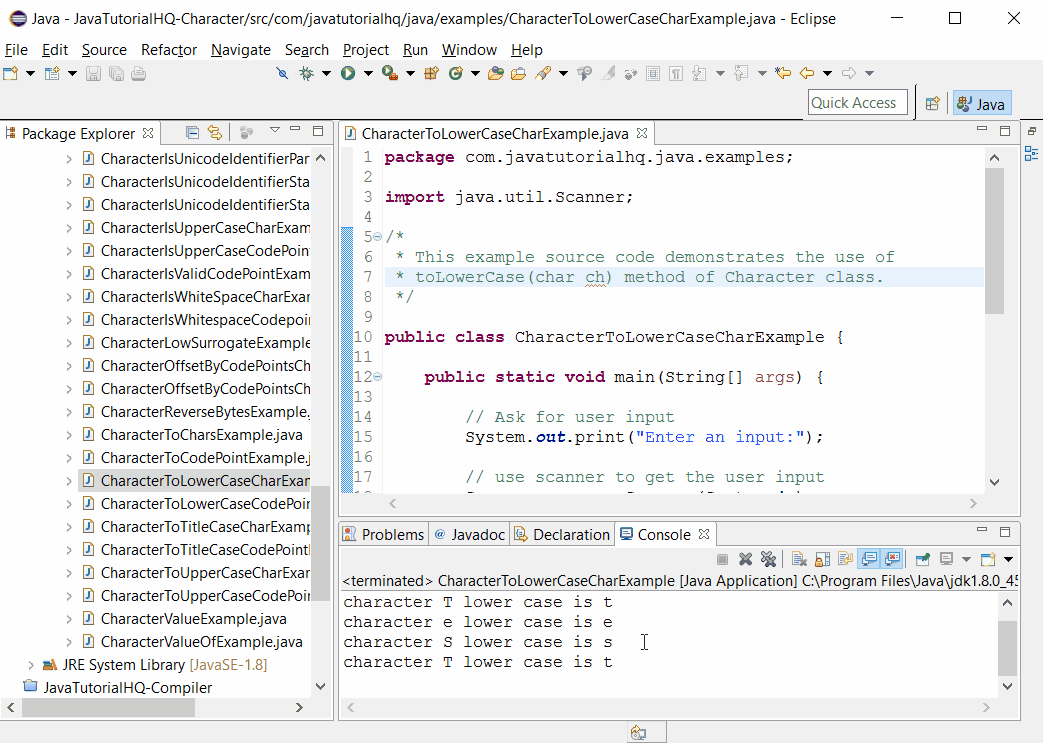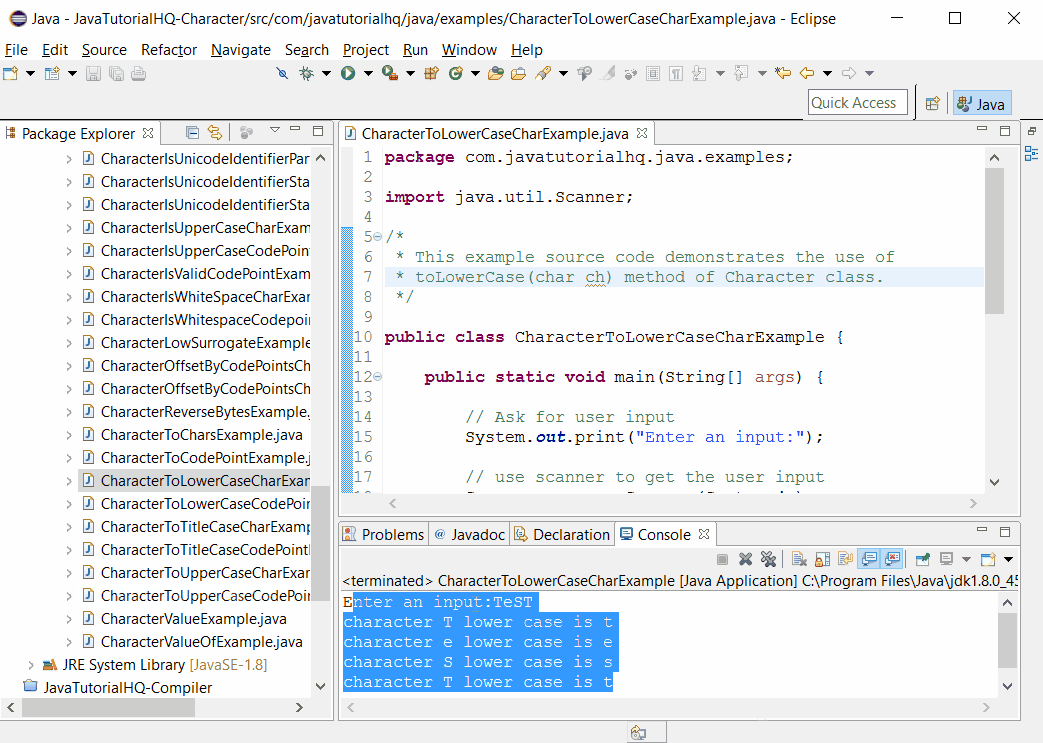
The primary method for converting a single character to lowercase is the Character.toLowerCase() method. This method takes a char as input and returns the lowercase equivalent if the character is uppercase. If the character is already lowercase or not an alphabetic character, the method returns the character unchanged.
Similarly, the Character.toUpperCase() method is used to convert a character to uppercase. Both methods rely on the Unicode standard to determine the appropriate case conversion, ensuring compatibility with a wide range of characters.
For converting entire strings, the String.toLowerCase() and String.toUpperCase() methods are available. These methods process each character in the string, applying the appropriate conversion and returning a new string with the converted characters. These string methods are particularly useful for handling larger text data, providing a straightforward way to achieve consistent case conversion across an entire string.
Using the toLowerCase() Method
The Character.toLowerCase() and String.toLowerCase() methods are the most commonly used functions for converting Java characters to lowercase. These methods are straightforward to use and provide reliable results for most case conversion needs.
To convert a single character to lowercase, the Character.toLowerCase() method is invoked with the character as its argument. This method checks the character's Unicode value and returns the lowercase equivalent if applicable. For example:
char uppercaseChar = 'A'; char lowercaseChar = Character.toLowerCase(uppercaseChar); When converting entire strings, the String.toLowerCase() method is preferred. This method iterates through each character in the string, converting it to lowercase as needed, and returns a new string with the converted characters. Here's an example:
String uppercaseString ="HELLO WORLD"; String lowercaseString = uppercaseString.toLowerCase(); These methods are highly efficient and easy to implement, making them the go-to choice for most case conversion tasks in Java. However, developers should be aware of special cases, such as non-English characters, where additional considerations may be necessary.
Handling Non-English Characters
When working with non-English characters, case conversion can be more complex due to variations in character sets and language-specific rules. Java's case conversion methods, such as Character.toLowerCase() and String.toLowerCase(), are designed to handle a wide range of characters, including those from different languages, thanks to their reliance on the Unicode standard.
However, developers should be aware of language-specific nuances that may affect case conversion. For example, certain languages have characters that do not have a direct uppercase or lowercase equivalent, or where the conversion rules differ from English. In such cases, additional logic may be required to ensure accurate conversion.
Fortunately, Java provides mechanisms for handling locale-specific case conversion, allowing developers to specify the desired locale when performing string conversions. By using the overloaded String.toLowerCase(Locale locale) method, developers can ensure that case conversion adheres to the rules of the specified language or region:
String turkishString ="İSTANBUL"; String lowercaseTurkishString = turkishString.toLowerCase(new Locale("tr", "TR")); This approach ensures that non-English characters are handled correctly, providing accurate and reliable case conversion across different languages.
Performance Considerations
When implementing case conversion in Java, it's important to consider performance implications, especially in applications that process large amounts of text data. While Java's built-in methods for case conversion are optimized for performance, developers should be mindful of potential bottlenecks and inefficiencies.
For single character conversions, the Character.toLowerCase() and Character.toUpperCase() methods are highly efficient, as they involve simple comparisons and bitwise operations. However, when dealing with strings, the String.toLowerCase() and String.toUpperCase() methods may incur additional overhead due to the creation of new string objects.
To optimize performance, developers can consider the following strategies:
- Avoid unnecessary conversions: Only convert characters or strings when necessary, and cache results if possible to reduce redundant operations.
- Use a
StringBuilder: For complex string manipulations involving multiple conversions, using aStringBuildercan improve efficiency by minimizing the creation of intermediate string objects. - Leverage parallel processing: For large data sets, consider using parallel processing techniques, such as Java's
parallelStream(), to distribute the workload and improve performance.
By applying these strategies, developers can ensure that case conversion operations remain efficient and do not negatively impact application performance.
Real-World Applications
Case conversion plays a crucial role in a variety of real-world applications, where text data needs to be processed accurately and consistently. From user input validation to data formatting and search functionalities, the ability to convert characters to lowercase is essential for delivering seamless user experiences and reliable software solutions.
One common application of case conversion is in form validation, where user input needs to be normalized to ensure consistency and accuracy. By converting input data to a uniform case, developers can simplify comparison logic and prevent issues such as duplicate entries or incorrect data processing:
String userInput ="JohnDoe"; if (userInput.toLowerCase().equals("johndoe")) { } Another application is in search and filtering functionalities, where case-insensitive comparisons are often required to deliver accurate results. By converting both search queries and data to a consistent case, developers can ensure that users receive relevant and comprehensive search results, regardless of case variations.
Additionally, case conversion is used in data formatting tasks, where text needs to be presented in a specific style for readability or branding purposes. Whether it's converting all text to lowercase for a minimalist design or applying specific case rules for headings, case conversion facilitates the creation of visually appealing and consistent interfaces.
Common Pitfalls and How to Avoid Them
While case conversion in Java is generally straightforward, there are several common pitfalls that developers should be aware of to avoid errors and ensure accurate results. Understanding these pitfalls and how to address them is essential for effective character handling.
One common pitfall is assuming that case conversion methods always produce the desired results for all characters, especially non-English ones. As mentioned earlier, certain languages have unique case conversion rules that may not align with English conventions. To avoid this issue, developers should use locale-specific conversion methods when working with international text:
String germanString ="ß"; String lowercaseGermanString = germanString.toLowerCase(Locale.GERMAN); Another potential pitfall is failing to account for special characters, such as punctuation marks, numbers, or symbols, which do not have case distinctions. When performing case conversion, it's important to recognize that these characters will remain unchanged, and developers should design logic accordingly to handle them appropriately.
Finally, performance issues can arise if case conversion is applied unnecessarily or inefficiently. As discussed earlier, optimizing conversion operations and minimizing redundant processing can help mitigate performance concerns, ensuring that applications remain responsive and efficient.
Advanced Techniques for Lowercase Conversion
For developers looking to expand their expertise beyond basic case conversion methods, there are several advanced techniques that can enhance the flexibility and capability of lowercase conversion in Java. These techniques cater to more complex scenarios and requirements, providing additional tools for robust text manipulation.
One advanced technique involves the use of regular expressions for more sophisticated text processing. By leveraging Java's Pattern and Matcher classes, developers can perform case-insensitive pattern matching and replacement, enabling them to handle complex text transformations with precision:
String text ="Hello, World!"; Pattern pattern = Pattern.compile("hello", Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher(text); String result = matcher.replaceAll("hi"); Another technique is the use of custom case conversion logic, which allows developers to define their own rules for converting characters to lowercase. This can be useful in scenarios where specific character transformations are required, such as for domain-specific languages or proprietary text formats:
char customToLowerCase(char ch) { if (ch == 'X') { return 'x'; } return Character.toLowerCase(ch); } For applications involving large-scale text processing, developers can also explore the use of parallel processing techniques and concurrent collections to distribute workloads and improve performance. By utilizing Java's concurrency utilities, such as ForkJoinPool or ConcurrentHashMap, developers can handle case conversion operations efficiently across multiple threads or processors.
These advanced techniques provide additional tools and strategies for developers seeking to enhance their text processing capabilities, catering to more complex and demanding requirements.
Best Practices for Character Handling in Java
To ensure efficient and reliable character handling in Java, developers should adhere to a set of best practices that promote consistency, accuracy, and performance. By following these guidelines, developers can avoid common pitfalls and deliver high-quality software solutions.
One key best practice is to always use the appropriate case conversion methods, such as Character.toLowerCase() and String.toLowerCase(), to ensure accurate and consistent results. Developers should also be mindful of locale-specific rules and use locale-aware methods when working with international text.
Another best practice is to design code with performance in mind, minimizing unnecessary conversions and optimizing string manipulations. Utilizing efficient data structures, such as StringBuilder, and leveraging parallel processing techniques can help improve performance and reduce overhead.
Developers should also prioritize code readability and maintainability, using clear and descriptive variable names, comments, and documentation to facilitate understanding and collaboration. By writing clean and organized code, developers can ensure that character handling operations are clear, concise, and easy to maintain.
Finally, comprehensive testing and validation are essential to verify the accuracy and reliability of case conversion logic. Developers should implement thorough test cases to cover various scenarios, including edge cases and international characters, ensuring that their code performs as expected under different conditions.
Troubleshooting Case Conversion Issues
Despite best efforts, developers may encounter issues related to case conversion in Java, particularly when dealing with complex text data or language-specific rules. Troubleshooting these issues requires a systematic approach to identify the root cause and implement effective solutions.
When facing unexpected case conversion results, developers should first verify that the correct methods are being used and that any locale-specific considerations have been accounted for. Reviewing the input data for special characters or anomalies can also help identify potential causes of errors.
Debugging tools, such as breakpoints and logging, can be valuable for tracing the execution flow and pinpointing where issues occur. By analyzing the output at each step of the conversion process, developers can gain insights into potential discrepancies and make necessary adjustments.
In cases where performance issues arise, developers should profile their application to identify bottlenecks and inefficiencies. Tools such as Java's built-in profilers or third-party performance analyzers can provide detailed information on resource usage and execution times, guiding optimization efforts.
By applying these troubleshooting techniques, developers can effectively address case conversion challenges, ensuring accurate and reliable text processing in their Java applications.
Future Trends in Java Character Processing
As technology continues to evolve, the landscape of character processing in Java is also expected to change, driven by advancements in language features, internationalization, and performance optimization. Staying informed about these trends can help developers anticipate future developments and adapt their skills accordingly.
One emerging trend is the increased focus on internationalization and multilingual support, as applications become more global in reach. Java's continued commitment to supporting diverse character sets and languages will likely lead to enhancements in character handling capabilities, enabling developers to build applications that cater to a broader audience.
Performance optimization remains a key area of interest, with ongoing efforts to improve the efficiency of text processing operations. Advances in hardware and parallel processing techniques are expected to influence how developers approach character conversion, offering new opportunities for high-performance applications.
Additionally, the rise of artificial intelligence and machine learning is poised to impact character processing, as developers seek to integrate natural language processing capabilities into their applications. This may involve leveraging machine learning models for more sophisticated text transformations and case conversions, enhancing the capabilities of Java applications.
By staying abreast of these trends, developers can position themselves to take advantage of new opportunities and innovations in Java character processing, ensuring their skills remain relevant and cutting-edge.
FAQs
1. How do I convert a Java character to lowercase?
To convert a Java character to lowercase, use the Character.toLowerCase() method, which returns the lowercase equivalent of the character if applicable.
2. Can I convert entire strings to lowercase in Java?
Yes, you can convert entire strings to lowercase using the String.toLowerCase() method, which processes each character in the string and returns a new string with the converted characters.
3. How do I handle non-English characters during case conversion?
To handle non-English characters, use locale-specific methods such as String.toLowerCase(Locale locale) to ensure accurate conversion based on the language or region.
4. What are common pitfalls to avoid when converting characters to lowercase?
Common pitfalls include assuming all characters have a direct lowercase equivalent and failing to account for locale-specific rules. Be sure to use appropriate methods and consider language nuances.
5. How can I improve performance when converting characters to lowercase?
To improve performance, minimize unnecessary conversions, use efficient data structures like StringBuilder, and consider parallel processing techniques for large data sets.
6. Are there advanced techniques for case conversion in Java?
Yes, advanced techniques include using regular expressions for complex transformations and defining custom conversion logic for specific requirements, providing greater flexibility and control.
Conclusion
Converting Java characters to lowercase is a vital skill for any Java developer, offering a range of applications from data normalization to user interface consistency. By understanding the methods and best practices for case conversion, developers can ensure their applications are robust, efficient, and capable of handling diverse text data.
Throughout this guide, we've explored the various techniques and considerations for converting characters to lowercase, including handling non-English characters, optimizing performance, and avoiding common pitfalls. By applying these insights, developers can enhance their text processing capabilities, delivering high-quality software solutions that meet the needs of users worldwide.
As the field of Java character processing continues to evolve, staying informed about emerging trends and technologies will be essential for maintaining a competitive edge. By embracing new advancements and refining their skills, developers can ensure they remain at the forefront of this dynamic and ever-changing domain.