What exactly is the difference between auprc vs auroc? If you've ever delved into the world of machine learning and data science, you've likely encountered these terms. Both AUPRC (Area Under the Precision-Recall Curve) and AUROC (Area Under the Receiver Operating Characteristic Curve) are crucial metrics used to evaluate the performance of classification models. But why do we need two different metrics, and what makes them distinct from each other? In this comprehensive guide, we'll explore these metrics in-depth, offering insights into their applications, strengths, and limitations. By the end, you'll have a clear understanding of when to use each metric and how they can enhance your model evaluation process.
The significance of choosing the right evaluation metric cannot be overstated in the realm of machine learning. Each metric provides unique insights into the performance of a model, especially when dealing with imbalanced datasets. It's essential to understand the nuances of auprc vs auroc to make informed decisions that align with the specific goals of your project. In this detailed article, we will break down the concepts of precision, recall, true positive rate, and false positive rate, all of which are pivotal to comprehending these metrics. We'll also present real-world scenarios where one might outperform the other, aiding you in selecting the best metric for your particular needs.
Whether you're a seasoned data scientist or just starting your journey in machine learning, understanding auprc vs auroc is crucial. This article is tailored to provide you with a foundational understanding of these concepts, while also delving into advanced topics for those looking to deepen their knowledge. With a blend of technical insights and practical examples, this guide aims to be an invaluable resource for anyone looking to master these essential evaluation metrics. So, let's embark on this enlightening journey and unravel the complexities of AUPRC and AUROC.
Table of Contents
- Introduction to Evaluation Metrics
- Understanding Precision and Recall
- The Basis of AUROC
- The Essence of AUPRC
- Comparing AUPRC and AUROC
- Real-World Applications
- Strengths of AUROC
- Strengths of AUPRC
- Limitations of AUROC
- Limitations of AUPRC
- When to Use AUPRC vs AUROC
- Case Studies
- Frequently Asked Questions
- Conclusion
- References
Introduction to Evaluation Metrics
In the field of machine learning, evaluation metrics are pivotal tools used to determine the performance of classification models. They provide insights into various aspects of a model's functionality, guiding data scientists in refining and optimizing their algorithms. Among these metrics, AUPRC and AUROC stand out due to their ability to offer a comparative analysis of classification performance. Understanding these metrics begins with a grasp of the concepts of precision, recall, and the trade-offs between them.
Evaluation metrics like AUPRC and AUROC are indispensable because they quantify how well a model can distinguish between different classes. This ability is especially critical in applications such as medical diagnostics, fraud detection, and spam filtering, where the cost of misclassification can be high. These metrics help in assessing whether a model is merely performing well by chance or genuinely has predictive power. As we delve deeper into the specifics of AUPRC and AUROC, it will become clear why choosing the right metric can significantly impact the interpretation of model results.
The journey to understanding evaluation metrics involves dissecting the underlying principles that form the basis of precision-recall and ROC curves. Each curve offers a different perspective on the model's performance, highlighting specific strengths and weaknesses. By evaluating these curves, we can identify the optimal balance between true positive rates and false positive rates, ultimately enhancing the model's effectiveness. This section sets the stage for a comprehensive exploration of how AUPRC and AUROC contribute to the evaluation process.
Understanding Precision and Recall
At the heart of AUPRC lies the concepts of precision and recall, two fundamental components that describe the performance of a classification model. Precision, also known as positive predictive value, measures the proportion of true positive results in all positive predictions made by the model. In simpler terms, it answers the question: "Of all the positive predictions, how many were actually correct?"
Recall, on the other hand, is also known as sensitivity or the true positive rate. It measures the proportion of true positive results out of all actual positives in the dataset. Recall addresses the question, "Of all the actual positive cases, how many did the model correctly identify?" Together, precision and recall provide a comprehensive view of a model's ability to make accurate positive predictions.
The balance between precision and recall is crucial because improving one often comes at the expense of the other. For instance, a model with high precision may have low recall if it is overly conservative in making positive predictions. Conversely, a model with high recall might have low precision if it predicts too many positives, including false positives. The precision-recall curve visualizes this trade-off, offering insights into the model's performance across different thresholds.
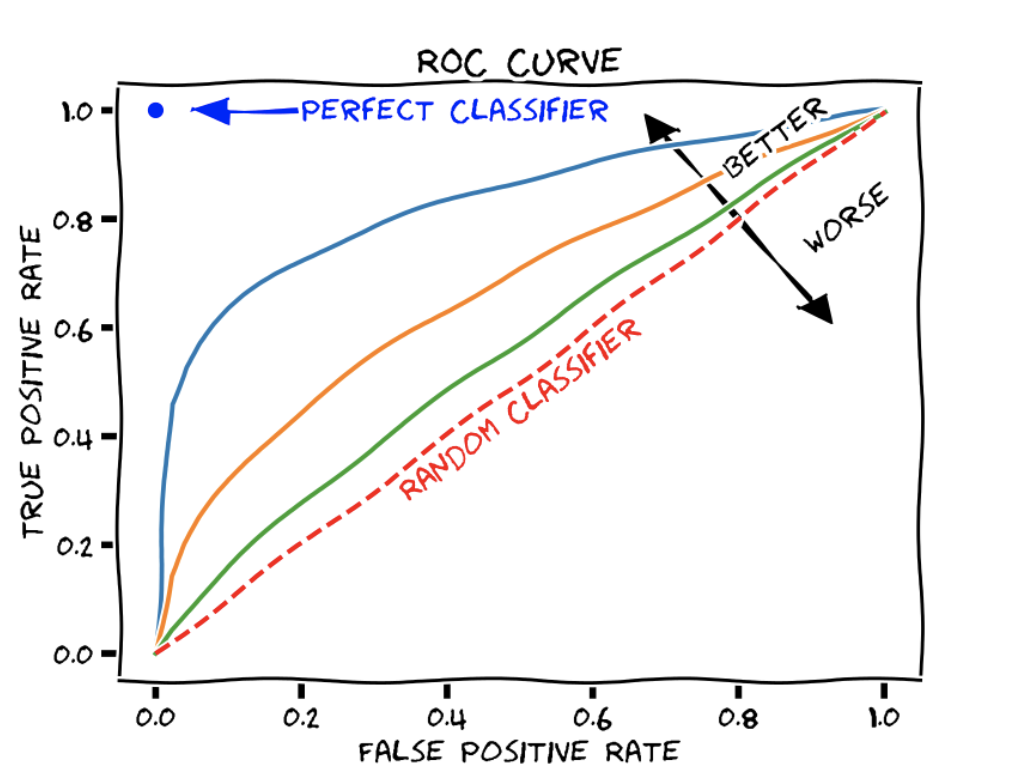
The Basis of AUROC
The AUROC, or the Area Under the Receiver Operating Characteristic Curve, is another critical metric that provides a comprehensive evaluation of a classification model's performance. The ROC curve is a graphical representation of the trade-off between the true positive rate (TPR) and false positive rate (FPR) across various threshold settings. The area under this curve (AUROC) quantifies the model's ability to discriminate between positive and negative classes.
One of the key advantages of AUROC is its ability to summarize the performance across all possible classification thresholds, providing a singular value that represents the model's overall discriminative power. A model with an AUROC of 0.5 indicates random guessing, while an AUROC of 1.0 signifies perfect discrimination. Typically, an AUROC greater than 0.7 is considered acceptable, though higher values are often sought in critical applications.
The ROC curve's emphasis on both TPR and FPR makes AUROC particularly useful in scenarios where the cost of false negatives and false positives are equally critical. However, in cases of highly imbalanced datasets, where one class significantly outnumbers the other, AUROC may not accurately reflect the model's performance, necessitating alternative metrics like AUPRC.
The Essence of AUPRC
AUPRC, or the Area Under the Precision-Recall Curve, is a metric that specifically addresses the challenges posed by imbalanced datasets. Unlike AUROC, which considers both false positives and false negatives, AUPRC focuses solely on the positive class, making it particularly useful in cases where the positive class is rare and false positives are less of a concern.
The precision-recall curve plots precision against recall for various threshold settings, and the area under this curve provides a single value summarizing the trade-off between the two. A higher AUPRC indicates that the model maintains high precision across a range of recall values, which is crucial when the cost of false negatives is high, such as in medical diagnosis or fraud detection.
One of the strengths of AUPRC is its ability to highlight a model's performance on the minority class, providing a more nuanced view of its effectiveness in scenarios where the positive class is of primary interest. However, like any metric, AUPRC has its limitations and may not be suitable for every situation, particularly when the negative class is equally important.
Comparing AUPRC and AUROC
When it comes to evaluating classification models, the choice between AUPRC and AUROC often depends on the specific context and goals of the analysis. Both metrics offer unique insights, but they cater to different aspects of model performance. AUROC is generally preferred in balanced datasets where the cost of false positives and false negatives are similar. It provides a comprehensive view of the model's ability to distinguish between classes across all thresholds, making it a suitable choice for many applications.
In contrast, AUPRC is more appropriate for imbalanced datasets where the positive class is rare, and the focus is on minimizing false negatives. The precision-recall curve's emphasis on precision and recall makes AUPRC particularly useful in scenarios where accurately identifying the positive class is critical. This makes it an ideal choice in fields like medical diagnostics, where missing a positive case can have severe consequences.
Ultimately, the decision between AUPRC and AUROC should be guided by the specific requirements of the task at hand. Understanding the strengths and limitations of each metric is essential for making informed decisions that align with the goals of the project. By leveraging the insights provided by both metrics, data scientists can develop more robust and effective models, tailored to the unique challenges of their applications.
Real-World Applications
The practical applications of AUPRC and AUROC extend across various fields, each with its unique challenges and requirements. In the realm of healthcare, for instance, both metrics play a pivotal role in evaluating models used for disease diagnosis and prognosis. The ability to accurately identify positive cases, even in the presence of imbalanced datasets, is crucial in ensuring timely and effective treatment.
Similarly, in the domain of finance, where fraud detection is a significant concern, AUPRC offers valuable insights into a model's ability to identify fraudulent transactions, which are often rare compared to legitimate ones. The precision-recall curve's focus on the positive class makes it particularly suited for this application, ensuring that false negatives are minimized while maintaining high precision.
In the field of cybersecurity, both AUPRC and AUROC are employed to assess models tasked with detecting potential threats and anomalies. Given the high stakes involved, the choice of metric can have profound implications on the effectiveness of threat detection systems. By leveraging the strengths of both metrics, organizations can enhance their security measures, safeguarding against potential breaches and attacks.
Strengths of AUROC
One of the primary strengths of AUROC is its ability to provide a holistic view of a model's performance across all classification thresholds. This makes it an invaluable tool for evaluating models in scenarios where the distribution of classes is relatively balanced, and both false positives and false negatives are of equal concern. AUROC's singular value offers a straightforward means of comparing different models, facilitating the selection of the most effective algorithm for a given task.
AUROC's emphasis on the trade-off between true positive rate and false positive rate ensures that the metric captures the model's ability to distinguish between classes effectively. This is particularly beneficial in applications where maintaining a balance between sensitivity and specificity is crucial, such as in spam filtering or credit scoring models.
Moreover, AUROC is less sensitive to class imbalance than AUPRC, making it a more versatile metric in diverse scenarios. Its ability to provide a comprehensive assessment of model performance makes it a popular choice for evaluating binary classifiers, particularly in fields where the cost of misclassification is evenly distributed between classes.
Strengths of AUPRC
AUPRC shines in scenarios where the positive class is rare, and the focus is on accurately identifying true positives. Its emphasis on precision and recall makes it particularly suited for applications where false negatives carry significant consequences, such as in medical diagnostics or fraud detection. The precision-recall curve's ability to highlight the trade-off between these two metrics offers a more nuanced view of model performance, particularly in imbalanced datasets.
By focusing on the positive class, AUPRC provides valuable insights into a model's ability to maintain high precision across varying levels of recall. This is crucial in scenarios where missing a positive case can have severe implications, ensuring that the model is optimized for maximum effectiveness in identifying true positives.
Furthermore, AUPRC's ability to capture the performance of a model in the context of the minority class offers a more targeted evaluation, particularly in cases where the positive class is of primary interest. This makes it an ideal choice for applications where the focus is on maximizing the detection of rare events, providing a more accurate assessment of a model's capabilities.
Limitations of AUROC
Despite its strengths, AUROC has certain limitations, particularly in the context of imbalanced datasets. In scenarios where one class significantly outnumbers the other, AUROC may not accurately reflect the model's performance, as it gives equal weight to both false positives and false negatives. This can lead to misleading interpretations, particularly when the positive class is rare and the primary focus is on minimizing false negatives.
Additionally, AUROC's singular value may not capture the nuances of model performance across different thresholds, particularly when the distribution of classes is skewed. This can result in an overestimation of a model's effectiveness, particularly in cases where the cost of misclassification is not evenly distributed between classes.
Moreover, AUROC's insensitivity to class imbalance can limit its utility in scenarios where the positive class is of primary interest. In such cases, alternative metrics like AUPRC, which offer a more targeted evaluation of model performance, may be more appropriate. Understanding these limitations is crucial for making informed decisions about when to use AUROC and how to interpret its results effectively.
Limitations of AUPRC
While AUPRC offers valuable insights into model performance in the context of imbalanced datasets, it is not without its limitations. One of the primary challenges is its sensitivity to class imbalance, which can result in misleading interpretations if not carefully considered. In scenarios where the negative class is equally important, AUPRC may not provide a comprehensive assessment of a model's capabilities.
Additionally, the precision-recall curve's focus on the positive class can lead to an overemphasis on recall at the expense of precision, particularly in cases where the cost of false positives is high. This can result in models that are optimized for identifying true positives but may generate a high number of false positives, particularly in applications where precision is critical.
Moreover, AUPRC's lack of a singular value to summarize model performance across all thresholds can make it challenging to compare different models directly. This can complicate the model selection process, particularly in scenarios where multiple algorithms are being evaluated. Understanding these limitations is crucial for making informed decisions about when to use AUPRC and how to interpret its results effectively.
When to Use AUPRC vs AUROC
The decision between AUPRC and AUROC ultimately depends on the specific context and goals of the analysis. AUPRC is generally preferred in scenarios where the positive class is rare, and the focus is on minimizing false negatives. This makes it an ideal choice for applications like medical diagnostics, fraud detection, and cybersecurity, where accurately identifying true positives is of paramount importance.
In contrast, AUROC is more appropriate in balanced datasets where both false positives and false negatives are of equal concern. Its ability to provide a comprehensive view of model performance across all thresholds makes it a suitable choice for many applications, particularly in fields where the cost of misclassification is evenly distributed between classes.
Ultimately, the choice between AUPRC and AUROC should be guided by the specific requirements of the task at hand, as well as the distribution of classes and the cost of misclassification. By understanding the strengths and limitations of each metric, data scientists can make informed decisions that align with the goals of their projects, ensuring the development of robust and effective models.
Case Studies
To illustrate the practical applications of AUPRC and AUROC, let's explore a few case studies that highlight their strengths and limitations in real-world scenarios. In the healthcare sector, a study evaluating the performance of a model used to predict the onset of diabetes found that AUPRC provided a more accurate assessment of the model's ability to identify positive cases, particularly given the imbalanced nature of the dataset. By focusing on precision and recall, AUPRC offered valuable insights into the model's effectiveness in minimizing false negatives, ensuring timely diagnosis and treatment.
Similarly, a financial institution tasked with detecting fraudulent transactions utilized both AUPRC and AUROC to assess the performance of its models. While AUROC provided a comprehensive view of the model's discriminative power, AUPRC offered a more targeted evaluation of its ability to identify rare fraudulent events. By leveraging the strengths of both metrics, the institution was able to optimize its fraud detection system, minimizing false negatives while maintaining high precision.
In the realm of cybersecurity, a case study evaluating the performance of a model used to detect potential threats found that AUPRC offered valuable insights into its ability to identify rare anomalies. By focusing on the positive class, AUPRC provided a more nuanced view of the model's effectiveness in detecting potential threats, ensuring robust security measures and safeguarding against potential breaches.
Frequently Asked Questions
What is the primary difference between AUPRC and AUROC?
AUPRC focuses on the trade-off between precision and recall, making it ideal for imbalanced datasets where the positive class is rare. In contrast, AUROC evaluates the trade-off between true positive rate and false positive rate, providing a comprehensive view of model performance across all thresholds.
When should I use AUPRC over AUROC?
AUPRC is preferred in scenarios where the positive class is rare, and the focus is on minimizing false negatives. It's particularly useful in fields like medical diagnostics, fraud detection, and cybersecurity, where accurately identifying true positives is critical.
Can AUROC be misleading in imbalanced datasets?
Yes, AUROC can be misleading in imbalanced datasets as it gives equal weight to both false positives and false negatives. In such cases, AUPRC may provide a more accurate assessment of model performance, particularly when the positive class is rare.
Is it possible to use both AUPRC and AUROC together?
Yes, using both AUPRC and AUROC together can provide a comprehensive evaluation of model performance, particularly in scenarios where both false positives and false negatives are of concern. Leveraging the strengths of both metrics can enhance the model evaluation process.
How do precision and recall relate to AUPRC?
Precision measures the proportion of true positive results in all positive predictions, while recall measures the proportion of true positive results out of all actual positives. AUPRC evaluates the trade-off between these two metrics, offering insights into a model's ability to maintain high precision across varying levels of recall.
What are the limitations of AUPRC?
AUPRC's sensitivity to class imbalance can result in misleading interpretations if not carefully considered. Additionally, its lack of a singular value to summarize model performance across all thresholds can complicate the model selection process.
Conclusion
In conclusion, understanding the nuances of auprc vs auroc is crucial for selecting the right evaluation metric for your classification models. Both metrics offer unique insights into model performance, catering to different aspects of the analysis. AUPRC is ideal for imbalanced datasets where the positive class is rare, while AUROC provides a comprehensive view of model performance across all thresholds in balanced datasets. By leveraging the strengths of both metrics, data scientists can develop more robust and effective models, tailored to the specific requirements of their applications. As you continue your journey in machine learning, keep these insights in mind to enhance your model evaluation process and achieve optimal results.
References
For further reading and a deeper understanding of evaluation metrics in machine learning, consider exploring the following resources:
- Scikit-learn: Model Evaluation
- Towards Data Science
- KDnuggets
- Coursera: Machine Learning Courses
- DataCamp